NVIDIA introduced a game-changing tool called NVIDIA NIM (Neural Inference Microservices) that promises to revolutionize how developers deploy AI models. This new technology aims to transform millions of developers into generative AI developers by simplifying the process of integrating AI capabilities into applications.
What is NVIDIA NIM?
NVIDIA NIM is a set of pre-packaged AI models that come in optimized containers. These containers are ready-to-use pieces of software that include everything needed to run an AI model efficiently. Think of them as pre-cooked meals for AI, developers can simply “heat and serve” these models in their applications without worrying about the complex “cooking” process.
Key Components and Technologies:
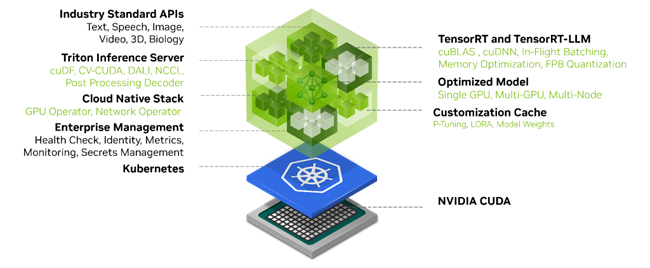
- CUDA Integration: NIM containers come pre-built with NVIDIA CUDA, allowing for seamless GPU acceleration out of the box. This integration ensures that developers can leverage the full power of NVIDIA GPUs without delving into low-level GPU programming.
- NVIDIA Triton Inference Server: Each NIM container incorporates the NVIDIA Triton Inference Server, a flexible inference serving software that supports multiple frameworks and optimizes for both CPU and GPU deployments.
- TensorRT-LLM: NIM leverages NVIDIA TensorRT-LLM, a powerful library for optimizing large language models (LLMs). This integration allows for significant performance improvements, especially for transformer-based architectures common in generative AI.
- Containerization Technology: NIM utilizes container technology, likely based on Docker, to ensure consistency across different deployment environments and simplify dependency management.
- Rapidly Deploy: with Kubernetes on major cloud providers or on-premises for production.
What is the difference between Nvidia Triton and Nvidia NIM?
| Aspect | Nvidia Triton | NIM (NVIDIA Inference Model) |
|---|---|---|
| Architecture | A standalone inference server supporting multiple frameworks (TensorFlow, PyTorch, ONNX, etc.) | Pre-packaged containers that include Triton along with optimized models and NVIDIA software stack |
| Deployment Model | Requires separate model management and often custom scripting for optimization | Offers a “deploy and run” model with pre-configured containers |
| Optimization Level | Provides a platform for custom optimizations, requiring expertise to fully leverage | Comes pre-optimized for specific models, reducing the need for manual tuning |
| Flexibility vs. Ease of Use | Highly flexible, supporting custom backends and complex deployment scenarios | Prioritizes ease of use and rapid deployment, potentially at the cost of some customization options |
| Integration Depth | Often requires integration work to fit into existing AI pipelines | Designed for seamless integration with popular AI platforms and tools |
| Resource Management | Offers fine-grained control over resource allocation and model instances | Provides automated resource management optimized for the packaged model |
| Target Use Cases | Ideal for organizations with complex, multi-framework AI deployments requiring custom optimizations | Suited for rapid deployment of generative AI models, especially in organizations without extensive AI expertise |
Want to create your own AI assistant that understands your business inside and out? Learn how to build a private AI assistant using NVIDIA NIM and Llama-3, trained on your own data!
Build Your Private AI Assistant with NVIDIA NIM and Llama-3
Check How NVIDIA NIM Compares Against Ollama: A Comprehensive Comparison
Ready to revolutionize your business with AI?
Experience the power of NVIDIA NIM firsthand at MBUZZ’s cutting-edge AI Experience Center in Dubai
As NVIDIA’s preferred partner for AI solutions, MBUZZ offers unparalleled expertise in implementing state-of-the-art AI technologies for businesses of all sizes. Whether you’re just starting your AI journey or looking to scale your existing AI initiatives, our team of experts is here to guide you every step of the way.



